Launching Arcana v2: Upgraded Vibes with More Languages and On-Prem ✨
Aug 20, 2025

At Rime, we're on a mission to make voice AI feel more human. Our deep linguistic and machine learning expertise helps us bridge the gap between humans and machines, driving millions of dollars in ROI for enterprise-scale voice agents.
Today we’re introducing Arcana v2, our next-generation text-to-speech. It's the most human speech synthesis model yet. Better, faster, and more expressive than the boundary-pushing Arcana v1.
Visit Rime Try to talk to our voices for free in your browser.
Unlike some unnamed competitors, Arcana v2 is available via API from day one.
With 300+ total voices and 35 flagship voices—18 English, 4 Spanish, 3 natively bilingual English/Spanish, 5 French, and 5 German—you’ve got options, and they’re all API-accessible.
Plus it's easy to instantly code switch between English, Spanish, and Spanglish. Just like a native speaker would.
Deploy via cloud, VPC, or on-prem. Stream via https or websockets with various audio formats, including telephony formats.
Behind the scenes, we’ve made a bunch of architectural improvements, which will let us fast follow with tons more voices, languages, and workflow tools. Look out for Hindi, Arabic, Japanese, Hebrew, Korean, Portuguese, and many more coming soon.
With Rime’s voices, companies are driving real impact today:
10% increase in call success for a high-growth startup
75% decrease in call abandonment for a national telecom
We’re motivated by the belief that it shouldn’t suck when you call your cellular carrier or bank.
Alright, let’s dive in!
Hear Voices
But first, don’t you want to hear how our new voices sound?
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/arcana-v2/mike-southern-roofing.mp3" data-caption="Hey there, this is Mike from Southern Roofing & Repair. Yeah, we’ve been swamped with calls this hurricane season—lots of folks need help patchin’ up roofs before the next big storm. Tell you what, let me put you on hold for just a sec, and I or someone from my team will be right back with ya."></div>
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/arcana-v2/vamos-a-san-francisco.mp3" data-caption="This weekend vamos a San Francisco to explore la ciudad. I’m thinking un poquito de hiking en Lands End y luego brunch in the Mission. Después maybe unos drinks en North Beach para cerrar la noche."></div>
If you’d like to have a full conversation we’ve got some options:
Rime Homepage (casual)
Rime Try (professional)
Rime Console (voice explorer)
Check out our docs for full implementation details
Since Arcana v2 is a direct 1:1 improvement on Arcana v1, we’ve kept the model API parameter the same (just arcana). So if you’re already building with Arcana, you don’t have to do anything extra. You’re already getting the upgraded voices!
(Psst. Here are two forkable open source Rime+LiveKit, Rime+Pipecat, and Rime+Hugging Face repos if you’d like to hack on the demo locally too.)
Unmatched Realism

From real-time customer conversations to crystal-clear narration, English output is now sharper, smoother, and far more human. This is the kind of upgrade you can hear instantly.
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/arcana-v2/acme-corp-support.mp3" data-caption="Hello, thank you for contacting Acme Corp Support. My name is Astra, how can I assist you today?"></div>
Plus here are some fun examples of paralinguistic features (nonverbal aspects of communication) that add authenticity and realism to the Arcana speech synthesis model. Shoot, I'm tellin' ya'll, ain't nobody else doing stuff like this!
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/arcana-v2/vocal-tsk.wav" data-caption="small vocal noise: tsk"></div>
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/arcana-v2/false-starts.mp3" data-caption="false starts, stuttering"></div>
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/arcana-v2/tauro-boom.mp3" data-caption="boom!"></div>
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/arcana-v2/glottal-stop.mp3" data-caption="small glottal stop between first two words"></div>
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/arcana-v2/breathwork.mp3" data-caption="breathwork"></div>
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/arcana-v2/he-didnt-even-bother.mp3" data-caption="he didn’t even bother to buy her a drink?!"></div>
While competitors train their models on audiobooks, podcasts, and youtube data, which sound overly polished and have a performative "influencer" accent, Rime is training on real conversations with everyday people. When your customers hear our voices, they have an intuitive sense that these are real, so their willingness to talk to the bot increases. That means increased revenue and reduced costs through improved customer satisfaction, call success, containment, etc.
Multi-Lingual Code Switching

Do you speak Spanglish? Glide between Spanish and English mid-sentence without a stumble. Fluent, natural, expressive bilingual speech because language isn’t always one thing at a time.
We also support French+English and German+English multi-lingual code switching.
<div data-src="https://pub-a388dd8413ab4c478adabdb2f61495b7.r2.dev/arcana-v2/ich-habe.wav" data-caption="Ich habe die Präsentation fürs team meeting fertig aber der final draft muss noch korrigiert werden, und der deadline pressure macht mich total fertig, verstehst du? "></div>
Enterprise Deploy Options
Arcana v2 lets you run on-prem or via websockets, with the flexibility to use your own GPUs.
Run Arcana entirely inside your own walls. No cloud hops, no external dependencies. Just raw, expressive voice generation under your control. Enterprise-grade privacy meets full creative power.
With websockets, stream voice in real time with ultra-low latency, no buffering, no dead air.
If you’re already using Arcana on-prem, please contact sales@rime.ai or your primary contact and we’ll share the Arcana v2 images with you.
Technical Report: Model Architecture
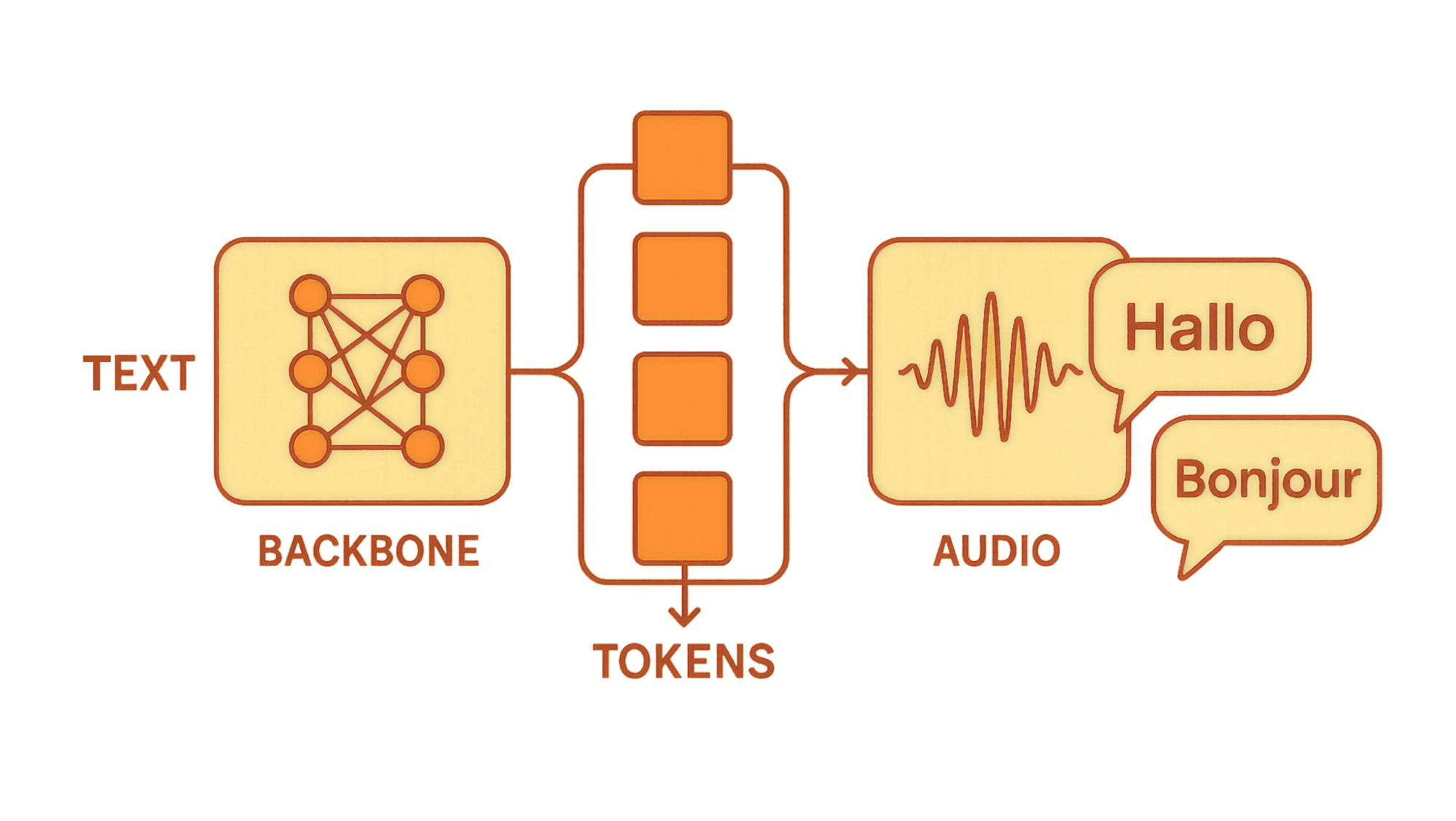
Arcana is a multimodal, autoregressive text-to-speech (TTS) model that generates discrete audio tokens from text inputs. These tokens are decoded into high-fidelity speech using a novel codec-based approach, enabling faster-than-real-time synthesis.
Backbone: A large language model (LLM) trained on extensive text and audio data.
Audio Codec: Utilizes a high-resolution codec to capture nuanced acoustic details.
Tokenization: Employs a discrete tokenization process to represent audio features effectively.
Training: Pre-trained from scratch and fine-tuned on Rime’s proprietary in-studio conversational data (more on that below).
Arcana is designed for smooth, rhythmic delivery in any language.
Rime’s Data Advantage

Rime’s unmatched voice realism comes from the world’s largest and most richly labeled proprietary dataset of natural, full-duplex speech, where two speakers talk naturally and sometimes overlap. This captures the true rhythm, spontaneity, and emotional texture of real human conversation.
Our PhD-level annotators use sociolinguistically sophisticated techniques to capture accents, idiolects, filler words, pauses, stress patterns, and multi-lingual code-switching. Every utterance is meticulously labeled with demographic and conversational context, giving Arcana v2 a deep understanding of how people really speak.
This dataset powers a three-stage training process—pre-training on large text-audio corpora, supervised fine-tuning on our proprietary recordings, and speaker-specific optimization for conversational reliability. The result is a model that can summon infinite voices, each as vivid and expressive as the people they’re inspired by.
For more information on Rime’s data practices, check out the original Arcana announcement.
Looking Ahead 👀

We’re continuing to expand Arcana’s linguistic range and expressive depth. Our custom pronunciation dictionary will grow to capture even more names, places, and specialized terminology, ensuring flawless delivery in every context. And with highly anticipated additions like Hindi, Japanese, and Arabic on the horizon, Arcana will soon bring its natural, human-like conversation to an even broader global audience.
Stay tuned as all of us at Rime keep advancing the frontier of voice AI!